Glimpse PoW
GANs
Introduction Generative Adversarial Networks (GANs) are a class of deep learning models introduced by Ian Goodfellow and his colleagues in 2014. The core idea behind GANs is to train a generator network to produce data that is indistinguishable from real data, while simultaneously training a discriminator network to differentiate between real an... Read more 26 Feb 2025 - 3 minute read
CLIP
Architecture Contrastive Language-Image Pre-training (CLIP) uses a dual-encoder architecture to map images and text into a shared latent space. It works by jointly training two encoders. One encoder for images (Vision Transformer) and one for text (Transformer-based language model). Image Encoder: The image encoder extracts salient features fr... Read more 26 Feb 2025 - 2 minute read
NerFs
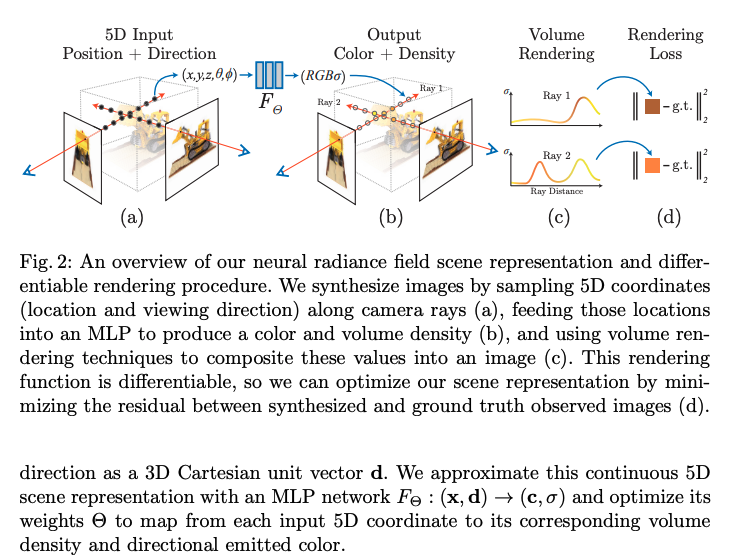
Pytorch implemntation from scratch Introduction Neural Radiance Fields are a way of storing a 3D scene within a neural network. This way of storing and representing a scene is often called an implicit representation, since the scene parameters are fully represented by the underlying Multi-Layer Perceptron (MLP). (As compared to an explicit repr... Read more 17 Feb 2025 - 2 minute read
LLD
Principles 1) SOLID Single Responsibility - This means that a class must have only one responsibility Open/Closed - Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification Liskov Substitution Principle (LSP) - Objects of a superclass should be replaceable with objects of its subclas... Read more 17 Feb 2025 - less than 1 minute read